Art & Tech
An Artist Invited Blind People to Use an A.I. Image Generator. The Unsettling Results Could Help Make Art More Accessible
Researchers tested the limitations of images created with text prompts.
. French sculptor. The Three Shades, before 1886. Bronze. Garden of Sculptures. Rodin Museum, Paris, France. Photo by: PHAS/Universal Images Group via Getty Images.")
Researchers tested the limitations of images created with text prompts.
Adam Schrader
 ShareShare This Article
ShareShare This Article
A project organized by artist Cosmo Wenman experimented with the use of artificial intelligence for blind users and has raised questions about whether the advancement in generative A.I. technologies can aid in accessibility for artists who are blind.
Wenman, known for his 3D design and fabrication art, worked on the quasi-academic art project with blind researchers Brandon Biggs, Lindsay Yazzolino, and Joshua Miele. The team started their work last fall and generated 4,110 images from text prompts input to Midjourney.
In describing the origin of the project, Wenman said he spent the last decade creating tactile exhibits and working with companies specializing in universal access, often consulting with researchers who are blind themselves to provide feedback for that design cycle.
“For the last year when these A.I. solutions started becoming available, I was just naturally interested in how this might interact with accessibility issues,” Wenman told Artnet News.
He said the ability of A.I. models and their creators to mine human art and imagery has created a “new form of accessibility.”
“With photography or even 3D scans of sculptures, we access a surrogate of that thing. With A.I., we are accessing elements of the thing broken down for us and more readily available for remixing,” Wenman said. “It’s astonishing. If a museum published a photograph, you could download it. But you’re not downloading understanding of it or breaking it down into concepts. A.I. does that.”
Wenman said programs like Midjourney find “weird and thematic intersections” in art that are not obvious to human eyes. He pointed to pictures generated from prompts written by Miele that share visual language with the sculptures of Auguste Rodin. Miele had attempted to design his own works in Rodin’s style based on his knowledge from having touched a few of the sculptor’s works.

Left: Joshua Miele via Midjourney. Right: Auguste Rodin, Spare Arms, Hands, and Bones. Images courtesy of Musée Rodin and Cosmo Wenman

Second from left: Joshua Miele via Midjourney. Left and top center: Auguste Rodin, Child with barely modeled body. Bottom center and right: Auguste Rodin, Angled Left Arm, and Child sitting on a mound. Images courtesy of Cosmo Wenman, Musée Rodin and Jérome Manoukian
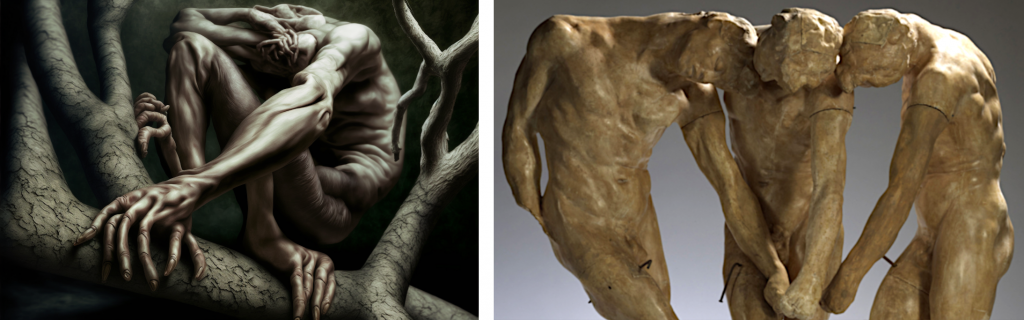
Left: Joshua Miele via Midjourney. Right: Auguste Rodin, The Three Shades (1886). Images courtesy of Cosmo Wenman and Musée Rodin.
“Thick limbs and stubby fingers, short men and twisted, interlocking partially embedded baby body parts, straining and struggling despite inevitable frustration and failure with infernal forces held back against barely better odds,” Miele wrote in his prompt.
The pictures output by Midjourney looked grotesque and gory in ways that do not obviously evoke Rodin’s best-known works like The Thinker (1904) and The Kiss (1882).
“I didn’t think Josh meant to create this visceral bloody imagery, and if he was using it on his own, he wouldn’t have known he had done that,” Wenman told Artnet News.
He shared images of Miele’s pieces, which seem closely inspired by Rodin’s oeuvre when examined more thoroughly.
“Crowded, fused, and misshapen embryonic nodes shadow the distorted silhouettes of menacing, hyperextended hands with painfully cramped fingers of plaster,” Wenman wrote in a blog post about the project. “Rodin’s exploration of the expressivity of irregular, oddly posed, and loosely modeled hands seems simpatico with Midjourney’s much-derided emphasis on gesture over accuracy, the emphasis Miele’s text clearly called for.”

Lindsay Yazzolino. Four images generated by Midjourney seeking to replicate Leonardo da Vinci’s The Last Supper. (2023) Images courtesy of Cosmo Wenman

Lindsay Yazzolino. A detailed look at one of four images generated by Midjourney seeking to replicate Leonardo da Vinci’s The Last Supper. (2023) Images courtesy of Cosmo Wenman
One grouping of images came from a prompt written by Yazzolino, who described Leonardo da Vinci’s The Last Supper (1948) in an attempt to have Midjourney replicate it. Her prompt reads, “famous painting depicting Jesus with his followers during the night before he is put on the cross.”
“Even with the Jesus imagery, they don’t look like Leonardo, but are evoking themes that can be stirring if that’s what you’re looking for,” Wenman said.
As the only seeing person on the team, he said he was “fascinated” by the results — many of which output visual illusions the artist had not anticipated.
“The Byzantine icon imagery of Jesus with his apostles, where they look like the silhouettes of the audience in front of them, I did not expect that,” Wenman said of one image output by Yazzolino’s prompt. “But looking back at what Lindsay described, it includes the idea of a ‘famous painting’ which implies people looking at it.”

Left: Michelangelo’s David (1504). Center and right: Brandon Biggs via Midjourney. Photo courtesy of Cosmo Wenman

Left: Leonardo’s Mona Lisa (1519). Center and right: Brandon Biggs via Midjourney. Photo courtesy of Cosmo Wenman
A.I. companies like Midjourney are openly talking about the issues, wanting to have precision and trying to give users more control over generated results based on the composition of their text input. Such advances are certain to make these tools more accessible for blind users, but could take away some serendipitous beauty. Wenman said chaos leads to visual intrigue when artists who are blind use image generators to create art.
“I hope that all these systems retain the ability to have some open-ended chaotic aspect to it,” Wenman said. “In Midjourney there is a command called chaos, a chaos factor of 0 to 100. That’s definitely really compelling but less utilitarian if you want a specific image.”
Wenman said A.I. companies will face challenges in closing an open loop that occurs where a blind user cannot vouch for the fidelity of the end result.
“The image technology can get better but a blind user is still not going to be able to evaluate the image,” Wenman said. “Josh talked about agency and how technologies enhance agency, as opposed to asking someone for help. It’s a touchy subject in blind issues, so the more a blind person can rely on something like text-to-image to be precise, the more they might find some value in expressing themselves.”

Top row: Joshua Miele. Bottom row: Brandon Biggs. Via Midjourney. Eight images of giraffe-like creatures output my text prompts written by the two researchers. Photo courtesy of Cosmo Wenman

Brandon Biggs. Eight images of elephantine creatures output by Midjourney from the text prompt “a large 4-legged animal with a long trunk, large ears, long tusks, hairless hide, and heavy.” Photo courtesy of Cosmo Wenman
Companies like Midjourney are trying to close that feedback loop by creating the ability to generate text from an image, which can already be done with models like OpenAI’s GPT-4. Such a back-and-forth system will get better and provide blind users with some feedback on generated images.
“When everyone can make beautiful imagery using these tools, who’s looking at it and why we’re looking at it is going to become more relevant,” Wenman said.
He said the team plans to curate their images into an exhibition and has discussed collaborating again to experiment with text-to-3D software. The artist plans to fabricate in bronze the 3D designs generated by the team’s text prompts.
“I think it’s important technology,” Wenman said of generative A.I. “I think the larger scale accessibility question, being able to integrate the thematic elemental make-up of a work, is really extraordinary. It’s essentially moveable type for visual rhetoric. That has never happened before.”
More Trending Stories:




